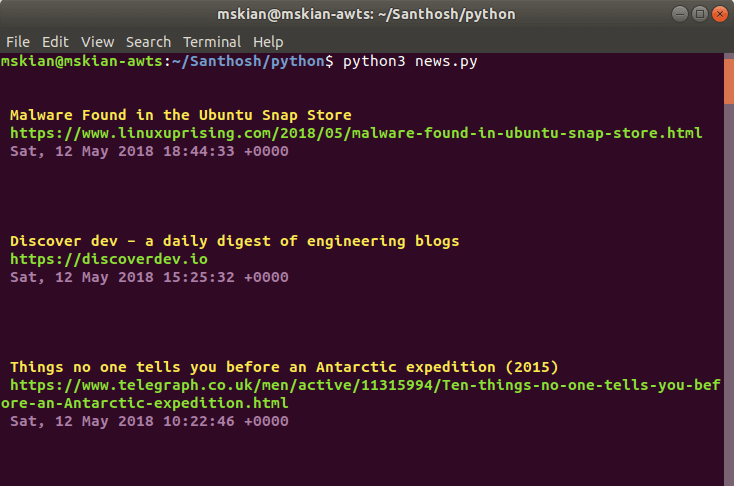
Create an Simple RSS Feed Reader using Python and Beautiful Soup 4.
Rss Feed scraping with BeautifulSoup
- import the Beautiful Soup 4 and urllib.request
from urllib.request import urlopen
from bs4 import BeautifulSoup
- Parse RSS feed items
def news(xml_news_url):
parse_xml_url = urlopen(xml_news_url)
xml_page = parse_xml_url.read()
parse_xml_url.close()
soup_page = BeautifulSoup(xml_page, "xml")
news_list = soup_page.findAll("item")
for getfeed in news_list:
print("\n")
print('\033[1;33m %s \033[1;m' %getfeed.title.text)
print('\033[1;32m %s \033[1;m' %getfeed.link.text)
print('\033[1;35m %s \033[1;m' %getfeed.pubDate.text)
print("\n")
- Add RSS Feed URL
#you can add 'xml' URL here from any websites/blog
NEWS_URL = "https://news.ycombinator.com/rss"
#now call news function
news(NEWS_URL)
- Full Code
#!/usr/bin/env python
from urllib.request import urlopen
from bs4 import BeautifulSoup
def news(xml_news_url):
parse_xml_url = urlopen(xml_news_url)
xml_page = parse_xml_url.read()
parse_xml_url.close()
soup_page = BeautifulSoup(xml_page, "xml")
news_list = soup_page.findAll("item")
for getfeed in news_list:
print("\n")
print('\033[1;33m %s \033[1;m' %getfeed.title.text)
print('\033[1;32m %s \033[1;m' %getfeed.link.text)
print('\033[1;35m %s \033[1;m' %getfeed.pubDate.text)
print("\n")
NEWS_URL = "https://news.ycombinator.com/rss"
news(NEWS_URL)
- Sample Output